벌써 마지막주차가 되었다.
시작할때는 분명 6주동안 과연 내가 완수할 수 있을지, 잘할 수는 있을까
참 고민도 많고 막막했다. 한권을 내가 과연 잘 끝낼 수 있을까?
막상 고민한게 무색하게 어찌저찌 잘 끝내고 여기까지 와서 되게 신기한 마음반, 뿌듯함 반이다.
6주차에는 회고록까지 있으니 이쯤 이야기하고 회고록에서 이야기 해보겠다.
마지막으로 배울 내용은 복잡한 데이터를 효과적으로 시각화 할 수 있는 객체지향 API에 대해서 이야기 해 볼 예정이다.
1. 객체지향 API로 그래프 꾸미기
(1) 객체지향 vs pyplot(절차지향)
우리는 저번시간까지, 데이터를 정제하고 이를 맷플롯립을 통해 표현하는 방법들을 공부했다. 그러면서, 우리는 그래프를 동시에 2가지를 그리는 경우에 대해 이야기 했었는데, subplot을 만들어 그리는 방식을 조금 더 집중적으로 배운다고 생각하면 된다. 기본적으로 하나의 그래프를 그릴 때는, 라이브러리에 있는 함수를 사용하여 간단하게 그릴 수 있다. 그러나 우리는 하나가 아닌 여러개의 그래프를 그려놓고 한번에 이를 파악해야하는 순간도 있기 때문에, 이를 쉽게 그릴 수 있도록 객체를 만들어 그리는 방식을 보통 많이 활용한다. 우선 객체지향과 pyplot 방식이 어떤 차이점이 있는지 코드를 통해 살펴보자.
import matplotlib.pyplot as plt
plt.rcParams['figure.dpi'] = 100
#pyplot 방식
plt.plot([1, 4, 9, 16])
plt.title('simple line graph')
plt.show()
#객체지향
fig, ax = plt.subplots()
ax.plot([1, 4, 9, 16])
ax.set_title('simple line graph')
fig.show()[출력결과]

다음 두 코드는 동일한 그래프를 결과로 반환한다. 그러나, 객체지향 방식은 pyplot 방식과 다르게, 각 그래프마다 설정을 달리 적용할 수 있도록 객체를 만들어 각 그래프에 대한 설정을 개별로 저장할 수 있다는 장점이 있다. 이러한 장점은 하나의 그래프를 그릴때는 체감이 되지않지만, 한번에 여러데이터를 한 페이지에 출력하는 것을 가정한다면 엄청 편리할 것이다.
(2) 한글 출력하기
가만보니 궁금한점이 있다. 제목이나 축을 표시할때 이때까지 영어를 사용했는데, 한글을 사용하면 안되는걸까? 사실은 사용해도 상관은 없다. 그러나 한글을 사용하고 싶다면, 한글을 지원하는 폰트를 사용해야한다. 기본적으로 맷플롯립에서 사용하는 글씨체(폰트)는 한글을 지원하지않아 한글이 깨져서 출력되는 현상이 있다. 책에서는 개발환경이 코랩이기 때문에 코랩에서 폰트를 적용하는 방법을 중점으로 이야기한다. 하지만 필자는 로컬에서 주피터노트북을 사용하기 때문에 이에 대한 내용을 중점으로 이야기 하겠다.
주피터 노트북과 같은 로컬환경에서 폰트를 적용하기전에, 폰트를 설치해야한다. 개발환경이 로컬이라면, 쉽게 사용하는 컴퓨터에 폰트를 설치해주기만 하면 준비 끝이다. 그러나 코랩의 경우 다음과 같이 폰트가 있는지 확인해보고, 없다면 설치 할 수 있다.
import sys
if 'google.colab' in sys.modules:
!echo 'debconf debconf/frontend select Noninteractive' | \
debconf-set-selctions
#나눔폰트 설치 및 적용
!sudo apt-get -qq -y install fonts-nanum
import matplotlib.font_manager as fm
font_files = fm.findSystemFonts(fontpaths=['/usr/share/fonts/truetype/nanum'])
for fpath in font_files:
fm.fontManager.addfont(fpath)위의 코드를 실행시키면 성공적으로 폰트가 코랩환경에서도 설치가 된다. 설치 이후에는 주의할 점이 있는데, 코랩이나 주피터노트북을 중간에 사용하는 도중에 폰트를 설치하게되면, 개발환경은 이를 바로 적용할 수가 없어 사용하게 되면 오류가 생긴다. 그렇기 때문에 설치를 중간에 했다면, 커널을 다시 재부팅하면 된다. 이후 모듈을 재호출하여 사용하면 정상적으로 작동된다.
이제 폰트를 설치했으니, 이를 본격적으로 적용해보도록하자. 기본적으로 맷플롯립에서 사용하는 폰트는 'sans-serif' 다. 현재 사용중인 폰트를 확인 하고싶다면 rcParams 객체에 'font.family' 속성에 저장되어있는 것을 출력하면 된다.
import matplotlib.pyplot as plt
plt.rcParams['figure.dpi'] = 100 #폰트 적용을 위해 재호출 후 기존설정 재설정하기
plt.rcParams['font.family'][출력결과]

기본적으로 가장 단순하게 폰트를 지정하는 방법은 rcParams 객체에 폰트 정보를 넘겨주어도 된다. 그러나 rc()를 통해 폰트를 지정하는 방법도 있다. rc() 방법은 폰트를 지정할 수 있음은 물론 폰트 크기등 까지를 한번에 지정할 수도 있다.
# rcParams를 통해 폰트 지정하기
plt.rcParams['font.family'] = 'NanumGothic'
print(plt.rcParams['font.family'])
# rc() 함수 사용하여 폰트 지정하기
plt.rc('font', family='AppleGothic', size=11)
print(plt.rcParams['font.family'], plt.rcParams['font.size'])
#필자는 맥을 활용하기에, 내장된 애플고딕을 사용하겠다.[출력결과]

잘 적용되는걸 확인 해보았으니, 이제 그래프의 제목을 한글로 한번 출력해보도록 하자.
plt.plot([1, 4, 9, 16])
plt.title('간단한 선 그래프')
plt.show()[출력결과]

(3) 도서개수 산점도 그리기
이제 본격적으로 데이터를 가지고 그래프를 객체지향 방식으로 그려보도록 하자. 우선 우리는 기존에 사용했던 도서데이터를 계속해서 활용할 예정이다.
import gdown
import pandas as pd
gdown.download('https://bit.ly/3pK7iuu', 'ns_book7.csv', quiet=False)
ns_book7 = pd.read_csv('ns_book7.csv', low_memory=False)
ns_book7.head()[출력결과]

파일을 잘 다운받은 것이 확인된다. 이중 우리는 전체를 출력하기에는 너무 힘드므로, 발행건수가 제일 많은 상위 출판사 30개를 가지고만 그려보도록 하겠다. 하여 상위 30개의 데이터를 추출해보도록 하자. 이는 value_count() 메서드와 불리언 슬라이싱을 사용하면 쉽게 추출해낼 수 있다.
top30_pubs = ns_book7['출판사'].value_counts()[:30]
# 해당 열의 각데이터 종류별로 개수를 계산하여 내림차순으로 정렬하여 반환한다.
# 불리언슬라이싱은 마지막 인덱스 하나 전을 범위로 하기 때문에 이를 주의하자.
top30_pubs
top30_pubs_idx = ns_book7['출판사'].isin(top30_pubs.index)
#상위 30개 출판사가 아니라면 False, 맞다면 True를 반환하여 불리언배열을 만든다.
top30_pubs_idx[출력결과]


데이터를 정제하기전에, 총 상위 30개의 출판사가 얼마나 많은 도서를 출판했는지가 궁금해졌다. 이를 잠시 확인해보자.
print(top30_pubs_idx.sum())[출력결과]

약 5만개의 책을 출판했다니, 은근 많다.(그냥 궁금해서 해보았다.) 5만개를 모두 산점도를 찍자니 조금 무리일 듯하니, 1000개 정도만 찍어보도록 하자. 그런데 우리 입맛대로 데이터를 추출하면 분석에 영향을 줄 수도 있으니, 무작위 확률로 추출하여 그래프를 그려보도록하자. 이는 sample() 메서드를 활용하면, 무작위로 표본을 추출해준다.
ns_book8 = ns_book7[top30_pubs_idx].sample(1000, random_state=42)
#random_state를 지정하면 다시 실행해도 동일한 표본을 반환한다.
#만약, 지정하지 않는다면 실행시 마다 무작위로 표본을 다시 추출한다.
ns_book8.head()[출력결과]

이제 데이터를 필요한만큼 추출했으니 이를 산점도로 그려보도록하자. 우리는 이왕 객체지향으로 그리기로 했으니, subplot을 이용하여 그려보자.
fig, ax = plt.subplots(figsize = (10, 8))
ax.scatter(ns_book8['발행년도'], ns_book8['출판사'])
ax.set_title('출판사별 발행 도서')
fig.show()[출력결과]

잘그려진것이 보인다. 그러나 그래프를 보고 분석을 들어가기에는 조금 문제가 있다. 바로, 어느 년도에 출판사마다 도서를 많이 대출했는지는 알 수가 없다는 것이다. 해당 그래프로는 대출을 했는지 안했는지 여부는 알 수 있으나, 이를 조금 더 디테일하게 얼마만큼을 했는지는 알기가 어렵다. 하여 마커의 크기 등 여러가지 설정을 변경하여 표현해보도록하자. 기본적으로 마커의 크기는 s 매개변수를 제공한다. 선그래프와 산점도는 마커 크기를 rcParams['line.markersize']를 통해 지정할 수 있으며 기본값이 6이다. 그리고, 이를 바탕으로 s 매개변수는 rcParams['line.markersize'] 값의 제곱을 사용한다.
fig, ax = plt.subplots(figsize = (10, 8))
ax.scatter(ns_book8['발행년도'], ns_book8['출판사'], s=ns_book8['대출건수'])
#s매개변수를 직접지정하면 마커크기가 동일해지지만, 입력데이터와 동일한 길이를 가진 배열로 지정하면
#데이터마다 다른 마커의 크기를 지정할 수있다.
ax.set_title('출판사별 발행 도서')
fig.show()[출력결과]
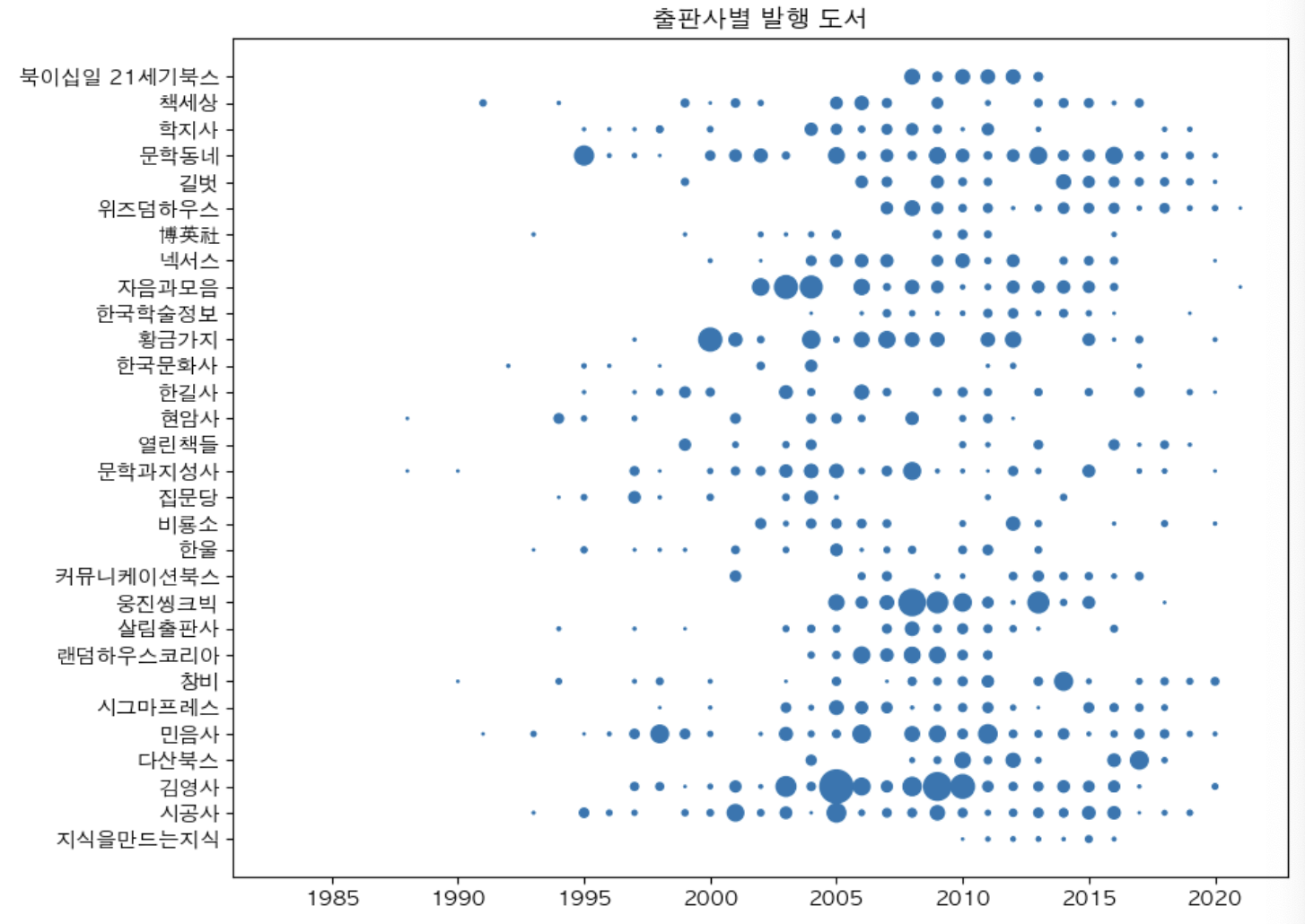
데이터의 크기별로 마커크기가 다르게 그려진 걸 확인 할 수 있어 이제는 출판사별로 출판이 많이 된 시기까지 알아 낼 수 있게 되었다. 이참에 제대로 한번 마커를 바꾸어 다르게도 표현해보도록하겠다. 마커를 수정할 수 있는 매개변수는 다음과 같다.
| 설정 기능 | 매개변수 |
| 투명도 조절 | alpha |
| 마커의 테두리 색 | edgecolor |
| 마커의 테두리 선 두께 | linewidth |
| 산점도 색 | c |
우리는 4가지의 매개변수와 기존 s 매개변수를 대출건수*2를 하여 좀더 가독성을 높여 그려보겠다.
fig, ax = plt.subplots(figsize = (10, 8))
ax.scatter(ns_book8['발행년도'], ns_book8['출판사'], \
linewidth=0.5, edgecolor='k', alpha=0.3,\
s=ns_book8['대출건수']*2, c=ns_book8['대출건수'])
#마커의 선두께 0.5, 테두리색상 검은색, 투명도 0.3, 마커 크기 대출건수*2, 마커 색상 대출건수
ax.set_title('출판사별 발행 도서')
fig.show()
[출력결과]

이제 효과적을 분석이 가능할 것 같다. 그러나 완벽을 추구하는 것이 좋지 않을까? 컬러맵이라는 걸 추가로 확용하면, 조금 더 데이터 건수에 따라 어떤 색인지를 표현해 줄 수 있다. 기본적으로 scatter 함수는 viridis 컬러맵을 사용한다. 우리는 주로 많이 사용하는 또다른 컬러맵인 jet 컬러맵을 활용하여 그려보자. 이때 cmap 매개변수를 통해 컬러맵을 지정할 수 있다. 그리고 컬러막대는 colorbar() 메서드를 객체에 전달하면 이를 그려준다.
fig, ax = plt.subplots(figsize = (10, 8))
sc = ax.scatter(ns_book8['발행년도'], ns_book8['출판사'], \
linewidth=0.5, edgecolor='k', alpha=0.3,\
s=ns_book8['대출건수']**1.3, c=ns_book8['대출건수'], cmap='jet')
#마커의 선두께 0.5, 테두리색상 검은색, 투명도 0.3, 마커 크기 대출건수**1.3, 마커 색상 대출건수
ax.set_title('출판사별 발행 도서')
fig.colorbar(sc)
fig.show()[출력결과]

2. 맷플롯립 고급 기능 배우기
이때까지 산점도, 막대그래프, 선그래프 등등 그래프를 그리는방법을 통달한 것 같다. 그러나 가장 중요한 것을 배우지 않았다. 이를 느꼈다면 분석에 조금 재능이 있을지도 모른다. 바로 굳이 여러그래프를 하나가 아닌 여러개로 봐야하냐는 것이다. 왜냐하면, 선그래프같은 경우에는 추이를 분석할 때 활용할 수 있는데, 단독이 아니라 여러 항목과 비교하며 추이를 비교할 때가 많다. 그렇다면 하나에 합치는 것이 조금 좋지 않을까? 하여 이를 조금 효율적으로 하기 위해 지금부터 이를 배워 보도록하자.
(1) 하나에 피겨에 여러 개 선 그래프 그리기
하나의 선그래프 위에 여러개의 선을 그리고 싶다면, 단순하게 plot() 함수를 여러번 호출하는 것 만으로도 충분히 할 수 있다.(너무 쉬워서 김빠지는가? 어렵게 나오면 그게 이상한거다.) 우리는 아까 활용했던 상위 30개의 출판사 인덱스를 그대로 활용하여 발행년도별 대출건수에 대한 그래프를 그려보도록 하자. 즉, 출판사 별로 발행년도 대비 대출건수의 추이를 한번에 파악해보겠다는 소리이다.
top30_pubs = ns_book7['출판사'].value_counts()[:30]
top30_pubs_idx = ns_book7['출판사'].isin(top30_pubs.index)
ns_book9 = ns_book7[top30_pubs_idx][['출판사', '발행년도', '대출건수']]
ns_book9 = ns_book9.groupby(by=['출판사', '발행년도']).sum()
#출판사별 연도별 대출건수를 표현하기 위하여 같은 연도의 대출건수는 하나로 합친다.
ns_book9 = ns_book9.reset_index()
# 인덱스를 초기화한다.
ns_book9[ns_book9['출판사'] == '황금가지'].head()
#황금가지라는 이름의 출판사에 해당하는 책데이터를 확인한다.[출력결과]

잘 집계된걸 확인 했으니 본격적으로 해당데이터로 그래프를 그려보도록 하자. 일단 우선적으로 비교하고자 하는 출판사 별로 데이터프레임을 각각 만들어 그래프를 그리자. 이때 아까 설명했듯이 한 피겨에 두가지를 표현하고자 하면 plot 함수를 두번 호출하면 된다.
line1 = ns_book9[ns_book9['출판사'] == '황금가지']
line2 = ns_book9[ns_book9['출판사'] == '비룡소']
fig, ax = plt.subplots(figsize = (8, 6))
ax.plot(line1['발행년도'], line1['대출건수'])
ax.plot(line2['발행년도'], line2['대출건수'])
ax.set_title('연도별 대출건수')
fig.show()[출력결과]

이제 두 출판사 간에 대출건수를 비교할 수 있다. 여기서 기능을 조금 살펴보면. 맷플롯립은 기본적으로 10가지의 선 색상을 활용한다. 그래서 색을 지정하지 않아도 자동으로 지정해준다. 그러나, 서로다른 10개 이상의 데이터를 표현할때는 중복된 색상을 사용하게 되므로, 구분이 쉽지않은 단점이 있다. 하여 이를 조금 해결하고자 맷플롯립에서는 legend() 메서드를 지원하여 범례를 추가 시킬 수 있다.
line1 = ns_book9[ns_book9['출판사'] == '황금가지']
line2 = ns_book9[ns_book9['출판사'] == '비룡소']
fig, ax = plt.subplots(figsize = (8, 6))
ax.plot(line1['발행년도'], line1['대출건수'], label = '황금가지')
ax.plot(line2['발행년도'], line2['대출건수'], label = '비룡소')
ax.set_title('연도별 대출건수')
ax.legend() #범례를 그래프에 추가한다.
fig.show()[출력결과]

이제 어느정도 선그래프를 그릴 수 있으니, 본격적으로 그래프를 그려보자. 일단 5개의 출판사를 한번에 그릴 것인데. 이번에는 반복문을 사용하여 파이쏘닉하게 그래프를 그려보도록 하겠다.
fig, ax = plt.subplots(figsize = (6, 8))
for pub in top30_pubs.index[:5]:
line = ns_book9[ns_book9['출판사'] == pub]
ax.plot(line['발행년도'], line['대출건수'], label=pub)
ax.set_title('연도별 대출건수')
ax.legend()
ax.set_xlim(1985, 2025) #x축의 데이터 시작과 끝을 지정한다.
fig.show()[출력결과]

(2) 스택영역 그래프
선 그래프를 많이 그려보았으니 이번에는 선그래프의 변형인 스택그래프를 그래보자. 스택그래프는 차곡차곡 쌓는 그래프라고 생각하면된다. 기존의 그래프는 각 그래프가 겹쳐지도록 그리지만 스택그래프는 이들이 서로 겹치지 않게 그린다고 생각하면 쉽다. 이를 그리려면 stackplot() 함수를 사용하면 된다.
스택그래프를 그리기 위해서는 y축의 데이터를 2차원 배열로 전달해야한다. 즉, x축에는 발행년도를, y축에는 출판사와 발행년도가 각각 행과 열로 된 2차원 배열로 주어야한다. 하여 이를 위해 데이터를 수정해보자. 이는 판다스의 pivot_table() 함수를 사용하면 된다.
ns_book10 = ns_book9.pivot_table(index='출판사', columns='발행년도')
ns_book10.head()[출력결과]
y축 데이터는 준비가 되었으니, x축 데이터를 위해 발행년도 열을 리스트로 바꾸어보자.
top10_pubs = top30_pubs.index[:10]
year_cols = ns_book10.columns.get_level_values(1)이제 축에 대한 데이터를 모두 완성했으니 스택영역 그래프를 그려보도록 하자. 스택영역그래프 또한 범례를 지원한다. 또한 범례 위치를 조정할 수 있는데, 이는 loc 매개변수를 통해 지정해주면 된다. 한번 그려보자. 이때 fillna를 사용하여 누락된 값을 0으로 채워 이상하게 그려지는 경우를 방지하자.
fig, ax = plt.subplots(figsize = (8, 6))
ax.stackplot(year_cols, ns_book10.loc[top10_pubs].fillna(0),\
labels=top10_pubs)
ax.set_title('연도별 대출건수')
ax.legend(loc = 'upper left') #좌측 상단에 범례를 생성한다.
ax.set_xlim(1985, 2025)
fig.show()[출력결과]
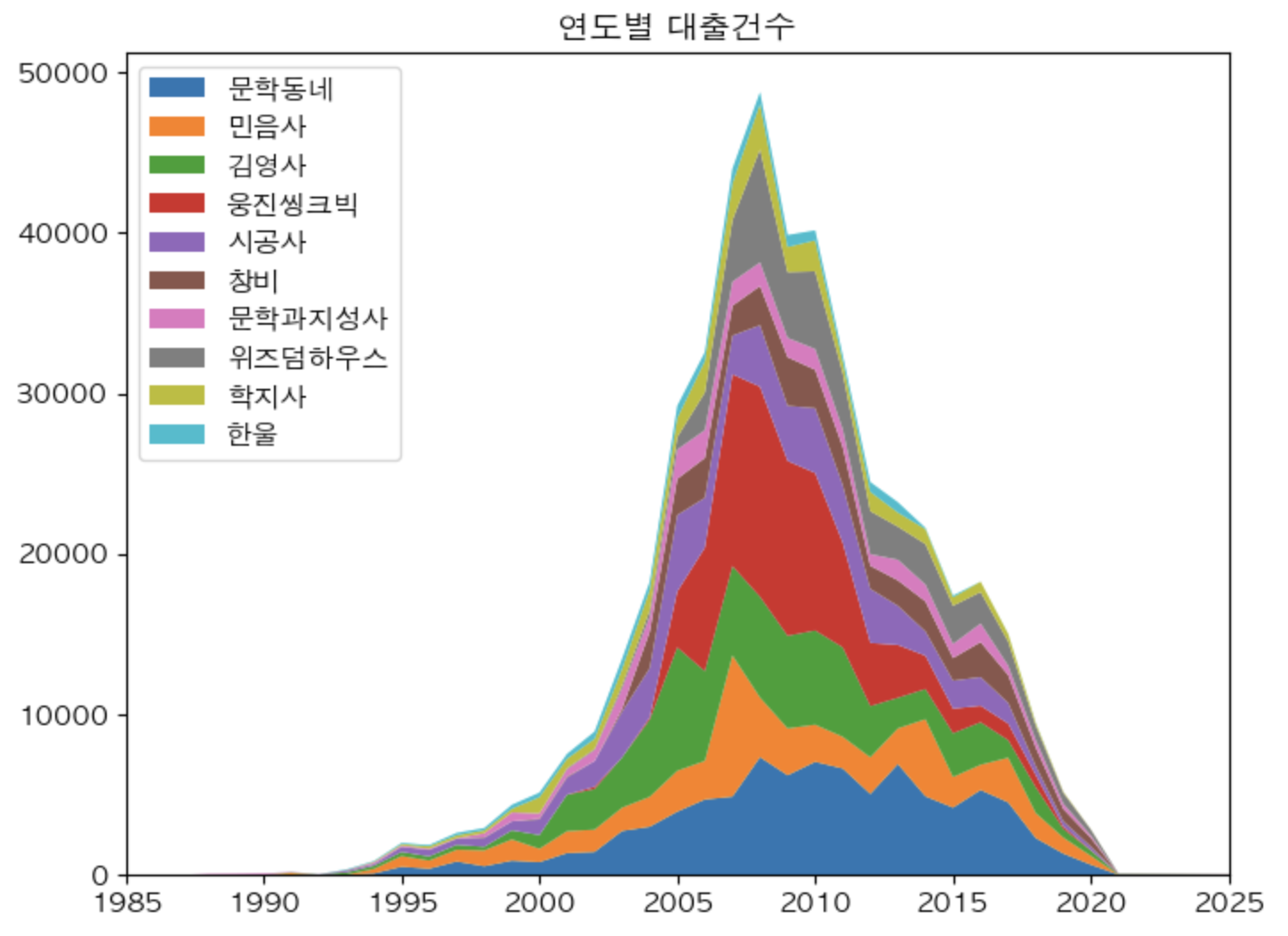
(3) 막대그래프
이전까지는 선그래프를 그렸는데, 변형으로 막대그래프 또한 같은 방식으로 그려보자. 막대그래프를 그리는 방법은 기존에 선그래프를 그렸던 코드에서 plot()함수를 bar() 함수로만 바꾸어 주면된다.
fig, ax = plt.subplots(figsize = (8, 6))
ax.bar(line1['발행년도'], line1['대출건수'], label = '황금가지')
ax.bar(line2['발행년도'], line2['대출건수'], label = '비룡소')
ax.set_title('연도별 대출건수')
ax.legend()
fig.show()[출력결과]

잘 그려진 것을 확인할 수있는데, 다만 막대그래프가 조금 겹쳐져있어서 보기가 조금 불편하다. 나란히 두고싶은데, 어떻게 하면 될까? 바로 막대 위치를 조금 이동하며 그려주면 된다. 기본적으로 막대그래프의 너비를 조정하는 width 매개변수는 기본값이 0.8로 되어있다. 하여 두개를 그리고 있으니, 절반인 0.4로 각각 지정하고 위치를 0.2씩 좌우로 이동하면 겹치지 않게 나란히 그릴 수있다.
fig, ax = plt.subplots(figsize = (8, 6))
ax.plot(line1['발행년도']-0.2, line1['대출건수'], width = 0.4, label = '황금가지')
ax.plot(line2['발행년도']+0.2, line2['대출건수'], width = 0.4, label = '비룡소')
ax.set_title('연도별 대출건수')
ax.legend()
fig.show()[출력결과]

나란히 그려져서 이제 보기가 예쁘다. 하지만 데이터가 여러개라면 두께를 한없이 나눠야 하므로 많은 종류는 표현하려면 막대가 거의 선에 가까워져서 오히려 문제가 될 것 같다. 하지만 괜찮다. 이런 경우에는 스택그래프로 그려버리면 된다. 웬걸, 그리려하는데 막대그래프는 스택그래프를 그려주는 함수가 따로 없다. 그렇다는 소리는 알아서 그려야한다. 그래도 여기까지 공부했으니 한번 그려보자.
스택그래프의 원리만 알면 사실 쉽게 그릴 수 있다. y값이 끝나는 지점에 차곡차곡 막대를 쌓는다고 생각하면 되는데, 즉 하나의 그래프가 끝나는 y좌표에 연달아 그리기만 하면 된다는 소리이다. 하여 이를 위해 리스트 내포를 통해 y좌표를 배열로 만들어 그려보도록하자. 일단 간단한 예제를 통해 연습해 보겠다.
height1 = [5, 4, 7, 9, 3]
height2 = [3, 2, 4, 1, 2]
plt.bar(range(5), height1, width=0.5)
plt.bar(range(5), height2, bottom=height1, width=0.5)
#bottom 매개변수를 사용하여, 막대그래프의 시작 y좌표를 지정해준다.
plt.show()[출력결과]

일단 쉽게 일일히 하나씩 좌표를 지정해주었지만 우리는 리스트내포를 통해 먼저 누적하여 높이를 그릴 수도 있다. 즉, 다시말하면 두 데이터합의 값으로 그래프를 그리고 위에 덮어서 다시 그리겠다는 소리이다.
height1 = [5, 4, 7, 9, 3]
height2 = [3, 2, 4, 1, 2]
height3= [ a+b for a, b in zip(height1, height2) ]
plt.bar(range(5), height3, width=0.5)
plt.bar(range(5), height1, width=0.5)
#bottom 매개변수를 사용하여, 막대그래프의 시작 y좌표를 지정해준다.
plt.show()[출력결과]

이제 원리를 어느정도 이해하였으니, 실제 데이터를 통해 그려보도록하자. 운이 좋게도 데이터를 누적하는 것은 판다스 데이터프레임에 cumsum() 메서드를 통해 쉽게 할 수있다. 이를 눈으로 어떻게 누적이 되는지 살펴 본 후 직접 해보자.
ns_book10.loc[top10_pubs[:5], ('대출건수', 2013):('대출건수', 2020)][출력결과]

ns_book10.loc[top10_pubs[:5], ('대출건수', 2013):('대출건수', 2020)].cumsum()[출력결과]

차이가 보이는가? 바로 열을 기준으로 다음행으로 넘어갈때마다 이전행의 데이터 값이 누적되어 더해지는 것을 알 수 있다. 이를 활용하여 이제 스택그래프를 그려보도록 하자.
ns_book12 = ns_book10.loc[top10_pubs].cumsum()
fig, ax = plt.subplots( figsize = (8,6))
for i in reversed(range(len(ns_book12))):
bar = ns_book12.iloc[i]
label = ns_book12.index[i]
ax.bar(year_cols, bar, label=label)
# 주의사항, 막대그래프를 위에 겹쳐서 그리는 방식이므로 가장 막대가 높은 그래프부터 그린다.
ax.set_title = ('연도별 대출건수')
ax.legend(loc='upper left')
ax.set_xlim(1985, 2025)
fig.show()[출력결과]

(4) 원그래프
이제 선, 막대는 마스터했다. 이제 원그래프만이 남았다. 원그래프는 다른말로 파이차트라고도 하는데, 전체 데이터 대비 각데이터의 비율을 가지고 부채꼴로 표현하는 그래프이다. 원그래프는 그래서 pie() 함수를 통해 그릴 수 있다. 해당 함수를 사용하면 자동적으로 비율은 계산하여준다. 여기서 원그래프를 그릴때 주의할 점은 기본적으로 원그래프는 데이터의 비율차이가 명확하지 않은경우 이를 비교하기가 매우 애매한 점이 있다. 하여, 원그래프는 각 비율을 명시적으로 표현하여 잘못된 정보를 제 3자에게 주지 않도록 조심해야한다.
data = top30_pubs[:10]
labels = top30_pubs.index[:10]
fig, ax = plt.subplots(figsize= (8,6))
ax.pie(data, labels=labels, startangle=90, \
autopct='%.1f%%', explode=[0.1]+[0]*9)
# 시작지점을 90도(12시)로 하여 반시계방향으로 그래프를 그린다. 이때 비율은 소수점 1째짜리까지 출력
# 그리고 explode 매개변수를 사용하여 문학동네의 영역을 떼어내어 그린다.
ax.set_title('출판사 도서비율')
fig.show()[출력결과]

(5) 서브플롯을 사용하여 하나의 영역에 그리기
지금까지 배운 4가지의 그래프를 서브플롯을 이용하여 한번에 그려보도록 하자. 서브플롯은 피겨객체라는 캔버스를 분할하여 그린다고 생각하면 된다. 즉, 행렬로 구역을 나누어서 각 위치에 그린다고 생각하면 된다.
fig, axes = plt.subplots(2, 2, figsize=(20, 16))
# 산점도
ns_book8 = ns_book7[top30_pubs_idx].sample(1000, random_state=42)
sc = axes[0, 0].scatter(ns_book8['발행년도'], ns_book8['출판사'],
linewidths=0.5, edgecolors='k', alpha=0.3,
s=ns_book8['대출건수'], c=ns_book8['대출건수'],
cmap='jet')
axes[0, 0].set_title("출판사별 발행 도서")
fig.colorbar(sc, ax=axes[0, 0])
# 스택 영역 그래프
axes[0, 1].stackplot(year_cols, ns_book10.loc[top10_pubs].fillna(0),
labels=top10_pubs)
axes[0, 1].set_title("연도별 대출건수")
axes[0, 1].legend(loc='upper left')
axes[0, 1].set_xlim(1985, 2025)
# 스택 막대 그래프
for i in reversed(range(len(ns_book12))):
bar = ns_book12.iloc[i] # 행 추출
label = ns_book12.index[i] # 출판사 이름 추출
axes[1, 0].bar(year_cols, bar, label=label)
axes[1, 0].set_title("연도별 대출건수")
axes[1, 0].legend(loc='upper left')
axes[1, 0].set_xlim(1985, 2025)
# 원 그래프
axes[1, 1].pie(data, labels=labels, startangle=90,
autopct='%.1f%%', explode=[0.1] + [0]*9)
axes[1, 1].set_title("출판사 도서 비율")
fig.savefig('all_in_one.png')
fig.show()[출력결과]

3. [필수숙제] _ p. 344의 손코딩(맷플롯립의 컬러맵으로 산점도 그리기)을 코랩에서 그래프 출력하고 화면 캡처하기

'혼자 공부하는 > 데이터분석 with Python' 카테고리의 다른 글
| [혼공분석] 혼공학습단 13기를 마무리하는 회고록 (0) | 2025.02.23 |
|---|---|
| [혼공분석] 5주차_데이터 시각화하기 (1) | 2025.02.16 |
| [혼공분석] 4주차_데이터 요약하기 (0) | 2025.02.07 |
| [혼공분석] 3주차_데이터 정제하기 (0) | 2025.01.26 |
| [혼공분석] 2주차_데이터 수집하기 (0) | 2025.01.19 |